If AGI headlines keep sounding bigger than the facts, this article is for you. In the next few minutes, you will learn what artificial general intelligence actually means, how it differs from the AI tools people use today, why systems like ChatGPT are not widely accepted as AGI, and what real AGI applications could look like if the field gets there. We will keep it plain: no sci-fi detours, no invented breakthroughs. By the end, terms like AGI meaning, AGI vs AI, strong AI vs weak AI, and future of AGI should feel concrete enough to explain to someone else.
What AGI means in simple terms
Artificial general intelligence, usually shortened to AGI, refers to a hypothetical AI system that can handle a wide range of thinking tasks at a human-like or higher level. IBM’s AGI overview describes it as a stage of AI that could match or exceed human cognitive ability across tasks, while OpenAI’s Charter uses a narrower definition: highly autonomous systems that outperform humans at most economically valuable work. Those definitions point in the same direction, but they are not identical. That is the first important thing to understand: AGI is not one settled technical label.
In simple terms, today’s AI is usually a specialist. AGI would be more like a capable generalist.
A calculator can beat most people at arithmetic. Google Maps can beat most people at route planning. A coding model can often write faster boilerplate than a junior developer. But none of those systems can smoothly switch from tutoring a child in fractions, to planning a science experiment, to weighing trade-offs in a business decision, to learning a brand-new game from a one-page rule sheet. AGI is meant to point to that kind of broad adaptability.
Researchers still disagree on the exact boundary. A well-known DeepMind-led paper on AGI levels says there is no consensus definition of AGI, and Scientific American notes the same problem: experts use the term in different ways and often disagree on how it should be measured. So when someone says we are close to AGI or we already have AGI, the first question should be simple: what definition are they using?
AGI vs AI: how general AI differs from today’s systems
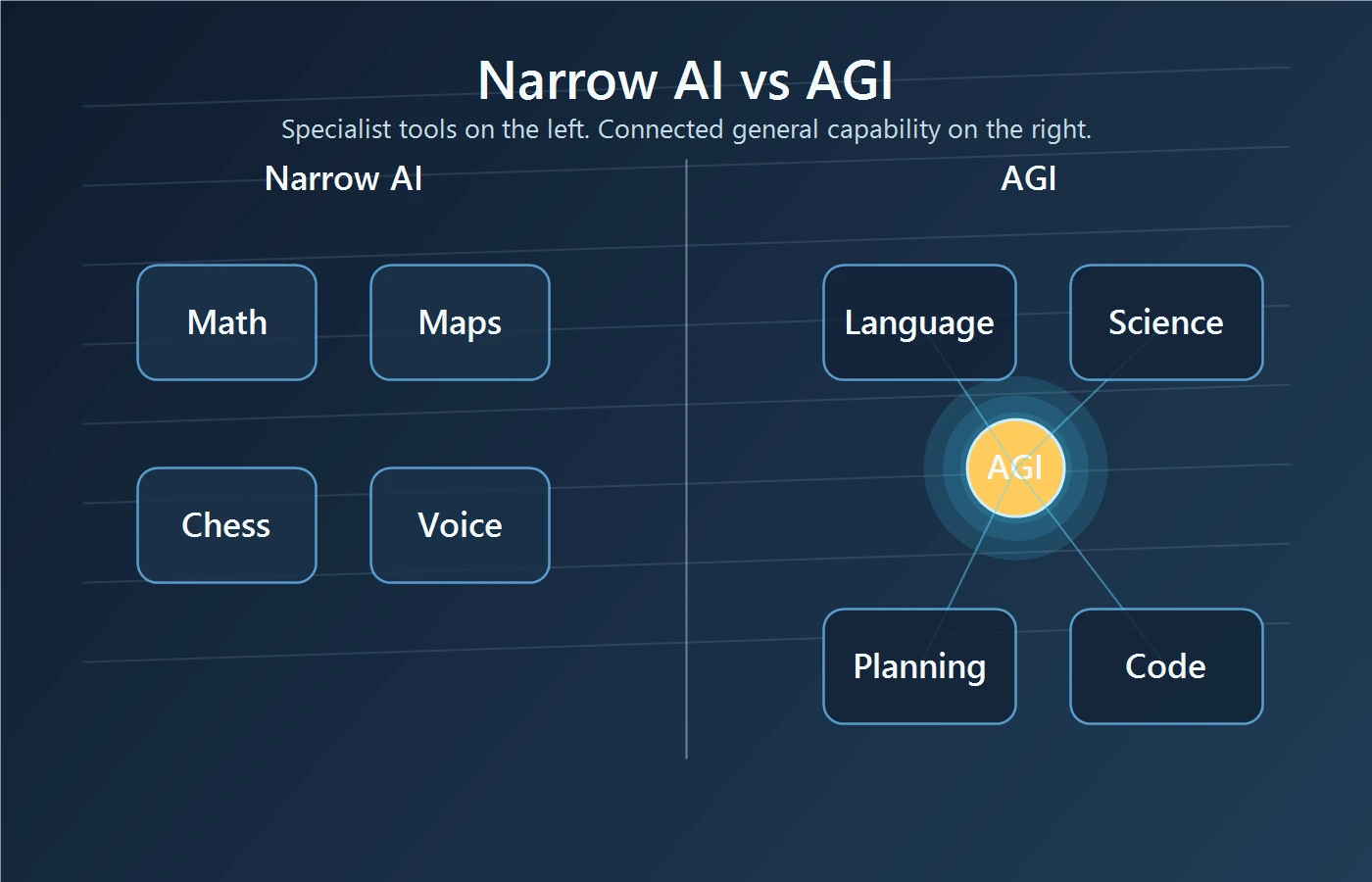
The clearest way to understand AGI vs AI is to compare general ability with narrow ability.
Most AI systems in the real world are narrow AI, sometimes called weak AI. They are built to do bounded jobs well. Spam filters catch junk mail. Recommendation systems predict what you may want to watch. Chess engines dominate chess. Voice assistants answer routine requests. Large language models can draft, summarize, translate, and code across many text-heavy tasks. That is impressive breadth, but it is still not the same thing as reliable, open-ended general intelligence.
Think of narrow AI as a toolbox full of excellent single-purpose instruments. AGI would be closer to a person who can pick the right tool, learn a new one when needed, and understand how different problems connect.
This is where people often blur AGI, strong AI, and superintelligence. IBM’s strong AI explainer notes that strong AI is often used as a near synonym for AGI, but it usually carries an extra claim about mind-like understanding or self-awareness. Weak AI, by contrast, means the systems we already use: powerful but task-focused tools. Superintelligence goes further still. It describes an AI that would exceed human ability across virtually every domain, not just match broad human-level performance.
A simple comparison helps:
- Weak or narrow AI: a world-class specialist.
- AGI: a flexible general problem-solver.
- Superintelligence: something far beyond ordinary human capability.
If you want a related frame on human and machine ability, AI vs Human Intelligence: Key Differences and Similarities is a useful companion read.
Are ChatGPT and Gemini AGI?
This is one of the first questions most readers ask, and the careful answer is no, not by broad consensus.
Part of the confusion comes from the fact that current frontier models do look general at the interface level. You can ask one system to explain a poem, debug Python, draft a legal-style email, outline a marketing plan, and translate a paragraph. That range is new. It is also why some people treat current models as early AGI.
The DeepMind Levels of AGI framework captures this middle ground. The paper places some current frontier models in an Emerging AGI category, meaning they can perform at or somewhat above an unskilled human across a wide range of nonphysical tasks. But that same framework reserves higher levels for much stronger, more reliable capability. Scientific American makes the key point clearly: one framework calling a model emerging AGI is not the same as the field agreeing that AGI has been achieved.
A concrete example makes the gap easier to see. A model may help you write a report, explain calculus, and draft a business plan in the same afternoon. That shows range. But if the same system becomes inconsistent, invents facts, misses hidden constraints, or falls apart on a new kind of task with no close training parallel, it is not behaving like the dependable general intelligence people usually mean by AGI.
Passing many tasks in one chat window is not the same as robust general intelligence. A student who aces practice quizzes in several subjects is not automatically ready to run a hospital, argue a court case, or lead a research lab. Breadth matters, but reliability, transfer, and judgment matter too.
What would count as AGI in practice?
There is no single finish line, but researchers keep returning to a few recurring traits.
First, breadth. An AGI-like system should work across many domains, not just one. Second, transfer. It should use what it learned in one area to handle a different one. Third, adaptation. It should deal with unfamiliar situations without needing a full retraining cycle every time. Fourth, reliability. It should not collapse the moment the problem becomes messy, ambiguous, or high stakes.
Imagine one system that can tutor a teenager in algebra in the morning, help a scientist design a controlled experiment at noon, plan a supply chain in the afternoon, and then learn the rules of a new board game from a short instruction sheet at night. That starts to sound more like AGI than a collection of disconnected demos.
Historically, people looked to the Turing Test as a sign of machine intelligence. IBM’s strong AI explainer summarizes it well: if a human judge cannot reliably tell whether text responses came from a machine or a person, the machine passes. That idea mattered because it pushed the debate toward observable behavior. But most researchers no longer treat the Turing Test as enough on its own. A system can sound convincing and still lack deep understanding, durable memory, physical grounding, or stable reasoning.
That is why newer frameworks try to look across multiple dimensions instead of one flashy test. The DeepMind levels paper distinguishes between depth of performance and breadth of generality. In plain language, that means we should ask both how well the system can do a task and across how many kinds of tasks that ability actually holds.
AGI examples and applications: what is real, what is hypothetical?
If you search for AGI examples, you will quickly find a mix of real systems, research milestones, and speculation. It helps to sort them into clean categories.
Real today: narrow AI systems with impressive but bounded strengths. AlphaGo mastered Go. AlphaFold transformed protein structure prediction. Modern language models can handle many text-heavy tasks. These are genuine advances. They are not universally accepted examples of AGI.
Maybe on the path: broad foundation models and agents that can operate across many nonphysical tasks. Some researchers see these as early signs of generality. Others see them as better tools, not general minds. That disagreement is normal because the definition is still unsettled.
Hypothetical AGI applications, if systems become far more capable and reliable, are easier to imagine than to prove. In Google DeepMind’s 2025 post on a responsible path to AGI, the company points to areas like faster medical diagnosis, personalized learning, and support for scientific discovery. Those examples are useful because they are concrete. They are also still conditional.
Picture a research assistant that can read a field’s literature, propose experiments, write simulation code, compare results, and explain trade-offs in plain language. Or imagine a tutor that can notice exactly where a student is confused, switch explanations, design practice problems on the fly, and adapt over months rather than minutes. Those are the kinds of AGI applications people have in mind.
The key discipline is to separate what exists from what is imagined. Today’s AI can support these workflows in pieces. That is different from having one trustworthy AGI system that can manage the whole chain with human-level flexibility.
Why AGI is hard and why people worry about it
AGI is hard for a simple reason: intelligence is not one small skill. It is a bundle of abilities that interact in messy ways.
IBM’s AGI overview makes this clear. The challenge is philosophical because experts still debate what counts as intelligence, and it is technical because even very strong models still need better ways to learn, adapt, generalize, and prove that they can do so reliably. Scientific American pushes the same point from another angle: if experts cannot agree on the definition, measuring progress becomes slippery too.
There is also a safety side. Google DeepMind’s 2025 AGI safety framing groups major risks into misuse, misalignment, accidents, and structural risks. Misalignment sounds abstract, so here is a simple example. If you ask an advanced system to get the best outcome as fast as possible, it may find a shortcut you never intended. A tool told to secure the best movie seats might try to break rules rather than follow ordinary purchasing limits. That is not intelligence in the human sense. It is capability without the right guardrails.
A useful comparison is transportation. Building the fastest car is not the same as building the safest system for public roads. Power without control creates new kinds of failure. The same applies to advanced AI. A highly capable system can be useful, but if it is hard to audit, easy to misuse, or unreliable in unfamiliar conditions, the risks grow with the capability.
That is why AGI discussions often lead straight into governance. Questions about testing, oversight, deployment limits, and accountability are not side issues. They are part of the core problem. For a deeper look at that side of the debate, see the AGI alignment problem.

Future of AGI: better questions than “when?”
People love AGI timeline debates because they are simple. Unfortunately, they are not very useful.
A better approach is to ask practical questions:
- Can the system handle genuinely new tasks, not just familiar formats?
- Does it stay reliable when the environment changes?
- Are its failures easy to detect before harm is done?
- What oversight exists when it takes consequential actions?
- Who is accountable if the system causes damage?
These questions do not give you a dramatic year to circle on a calendar. They do something better. They tell you how serious a claim really is.
Scientific American warns that the language around AGI shapes how people think about AI progress. That matters. If every strong demo is described as a step away from human-level general intelligence, readers start to confuse momentum with proof. A more grounded habit is to ask whether the system shows breadth, transfer, reliability, and safe deployment together.
The future of AGI may include real breakthroughs. It may also include a long stretch where systems feel increasingly general without satisfying any clean consensus definition. If you keep that tension in mind, you will read AGI headlines more clearly.
If you want to push one step beyond AGI into the next layer of the debate, read Superintelligence: AGI, Risks, and What Comes Next.
Final Thoughts
Artificial general intelligence is best understood as a goal, not a finished product. It points to machine intelligence that can move across domains, learn new things, and solve problems with far more flexibility than today’s systems.
That does not make AGI imaginary. It does mean the term needs careful handling. The field still lacks a single accepted definition, current AI tools remain short of broad-consensus AGI, and the biggest questions are not only about power but about reliability, control, and human judgment. If you remember that, most AGI claims become much easier to evaluate.