Recurrent neural networks, or RNNs, can look confusing when you first meet the term. You read that they have memory, then you see LSTM and GRU mentioned in the same breath, and before long the topic feels more technical than it needs to be. This guide is meant to fix that. You will learn what recurrent neural networks are, how RNNs work step by step, why sequence modeling matters, where RNNs are used, and why variants like LSTM and GRU were introduced. By the end, you should have a clear mental model of RNNs instead of a pile of disconnected definitions.
What recurrent neural networks are in simple terms
A recurrent neural network is a neural network designed for sequence data. Sequence data is any data where order carries meaning. A sentence is a sequence of words. A speech signal is a sequence of sound fragments over time. A week’s worth of temperature readings is a sequence too.
That is the key difference between an RNN and a simpler feedforward model. An RNN does not treat each input as a completely fresh case. According to IBM’s overview of recurrent neural networks and TensorFlow’s guide to working with RNNs, recurrent networks are built for sequential or time-series data and maintain an internal state across timesteps.
That internal state is why people say RNNs have memory. The word memory is useful, but it can also mislead beginners. An RNN is not storing a perfect copy of everything it has seen. It is carrying forward a learned summary of earlier inputs that may help with the next step.
Take a simple example. In the sentence, “I grew up in France, so I speak fluent ___,” the earlier word “France” should influence the missing word. Or think about energy demand through the day. A measurement taken at 3 p.m. makes more sense if the model also knows what happened at noon and 1 p.m. In both cases, what came earlier still matters now.
So the shortest plain-English answer to what are recurrent neural networks is this: they are neural networks built for ordered information, where earlier inputs can shape later outputs.
How RNNs work, step by step
The cleanest way to understand how RNNs work is to look at one small repeated operation instead of one giant black box.
Input, hidden state, and output
At each timestep, an RNN usually combines two things:
- the current input
- the hidden state from the previous step
The hidden state acts like a running summary of the sequence so far. A beginner does not need the equations to understand the idea. If the network has already processed the words “The clouds are dark, so bring an…,” the hidden state should preserve enough context to make “umbrella” a more likely next word than something unrelated.
The same logic applies to time series. Suppose an RNN is reading traffic measurements from the last several hours. The current reading matters, but so does the pattern leading up to it. The hidden state lets the network carry some of that context forward.
This step-by-step design is not just a teaching shortcut. Jeffrey Elman’s classic 1990 paper described a simple recurrent setup in which the hidden layer receives both the current input and a copy of the previous hidden activations. That is the foundation behind the beginner summary that RNNs remember what came before.
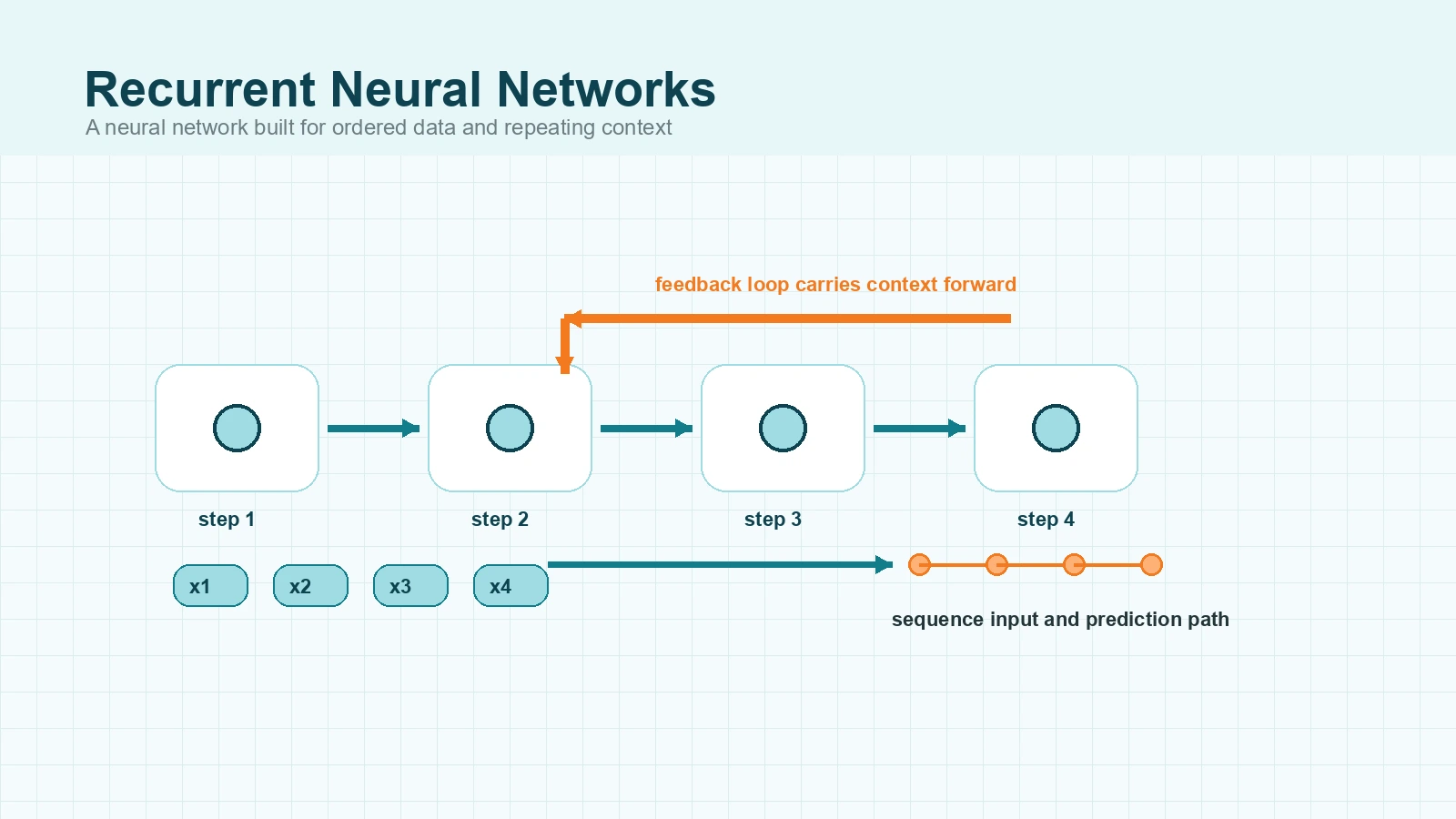
Why diagrams show the network repeated across time
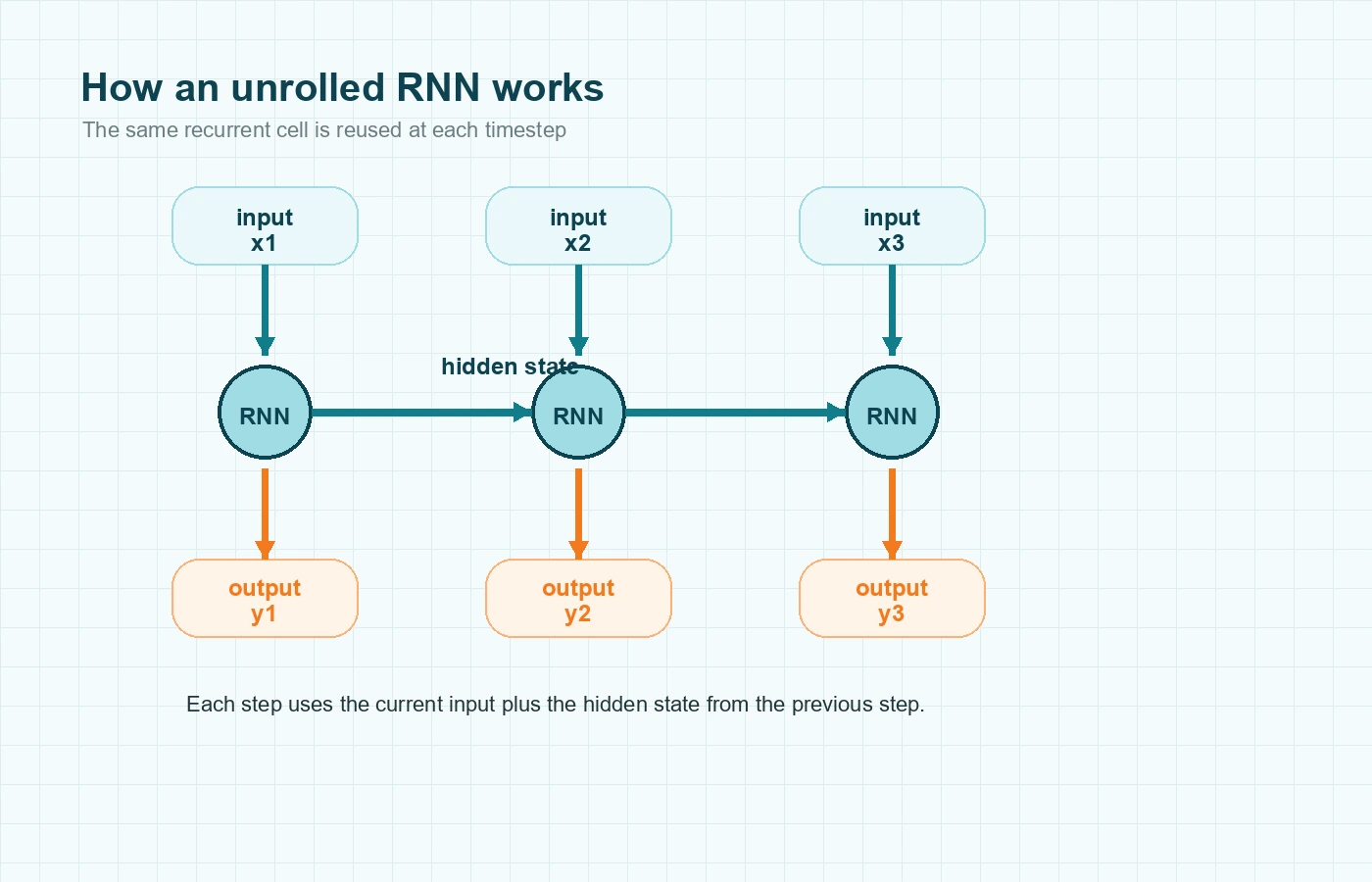
RNN diagrams are often drawn as a chain of nearly identical boxes. That picture is called an unrolled RNN. It is not showing many separate models. It is showing the same recurrent cell applied again and again across the sequence.
You can think of it like this:
- read the first item
- update the hidden state
- read the next item
- update the hidden state again
- keep going until the sequence ends
The structure repeats, but the hidden state changes because the context changes. That is why the model can react differently at step five than it did at step one, even though it is using the same core mechanism.
Shared weights and backpropagation through time
Another important idea is that the same weights are reused at every timestep. The RNN does not learn one set of parameters for the first word, another for the second word, and another for the third. It applies the same learned transformation repeatedly as the sequence moves forward.
Training still follows the same broad pattern used elsewhere in deep learning. The model makes predictions, compares them with the correct outputs, measures the error, and updates its weights. In recurrent networks, this backward learning pass is commonly called backpropagation through time, or BPTT.
The name sounds intimidating, but the idea is practical. If an RNN makes a wrong prediction near the end of a sequence, training may need to adjust how earlier steps were handled too. The error signal is pushed backward through the unrolled sequence so the shared weights can improve.
Why sequence modeling matters
Sequence modeling means learning from data where order is part of the meaning. That sounds obvious in language, but it matters in many domains.
Consider the two phrases “dog bites man” and “man bites dog.” The same words appear in both, but the order changes the meaning completely. A similar issue appears in time series. A list of numbers can show a trend, a seasonal cycle, or a sudden jump, but you lose that pattern if you shuffle the order.
This is the problem RNNs were designed to address. They are not only learning which features matter. They are also learning how information unfolds over time or across positions in a sequence.
RNN vs feedforward network
A feedforward neural network is often the right place to start when learning the basics of neural networks, and MindoxAI’s primer on artificial neural networks covers that foundation well. But a feedforward network usually treats its input more like a fixed snapshot.
An RNN is different. It reads the sequence piece by piece and updates its hidden state as it goes. That makes it better suited to problems where earlier context helps interpret the current step.
A quick comparison makes the difference clearer:
- A feedforward model might classify a single customer record using fixed columns such as age, income, and region.
- An RNN might read a sequence of customer actions over time and use the earlier actions to help interpret the later ones.
That does not mean feedforward models can never touch sequential data. You can still build features from fixed windows. But RNNs were created to model sequential dependence more directly.
Why vanilla RNNs struggle with long sequences
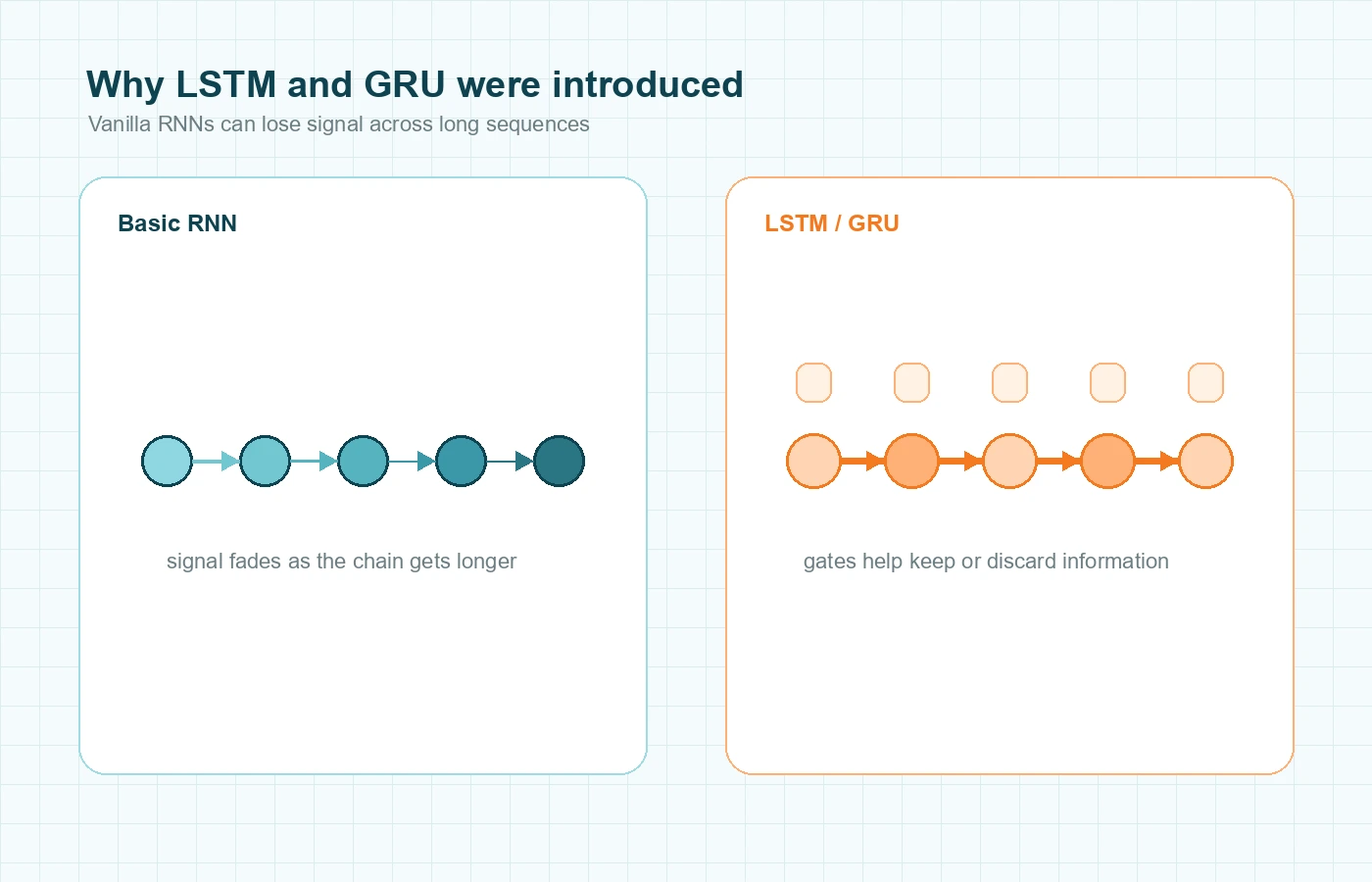
This is where many beginner articles get blurry. They say RNNs remember the past, then a few paragraphs later they say RNNs have trouble with long-term memory. The missing detail is that a simple RNN can often use nearby context, but it becomes harder to learn useful relationships when the important clue is many steps away.
Imagine the sentence, “The book on the shelf near the window, despite all the dust, was finally sold.” The model needs to keep track of “book” and not get pulled too far off course by the words in between. In time-series work, a model may need to connect a current reading to a much earlier pattern, not just the most recent points.
Vanishing gradients in plain language
One reason this becomes difficult is the vanishing gradient problem. Bengio, Simard, and Frasconi’s 1994 paper showed why learning long-term dependencies with gradient descent is hard in recurrent networks.
You do not need the full mathematics to understand the effect. During training, the learning signal has to travel backward through many timesteps. If the sequence is long, that signal can become very weak before it reaches the earlier steps that mattered. When that happens, the model has trouble learning from distant context.
A plain-language version is enough for most beginners: the farther the useful clue is from the place where the model makes its decision, the easier it is for the learning signal to fade.
Why LSTM and GRU were introduced
This is why LSTM and GRU matter so much in RNN discussions. They are not separate from recurrent networks. They are important recurrent variants designed to manage information flow more carefully.
According to the official Keras LSTM documentation, LSTM refers to the long short-term memory architecture introduced by Hochreiter in 1997. The Keras GRU documentation similarly identifies GRU as a gated recurrent unit based on Cho et al. 2014.
The beginner version of the story is simple:
- a basic RNN passes context forward, but useful details can fade
- an LSTM adds gates and a cell state to help preserve or discard information more deliberately
- a GRU uses a simpler gated design with a similar goal
So when readers search for recurrent neural networks, they are often really trying to understand a family of sequence models that includes vanilla RNNs, LSTMs, and GRUs.
Recurrent neural network examples and applications
RNN examples make the topic easier to hold in your head because the architecture starts to feel practical instead of abstract.
Text and language tasks
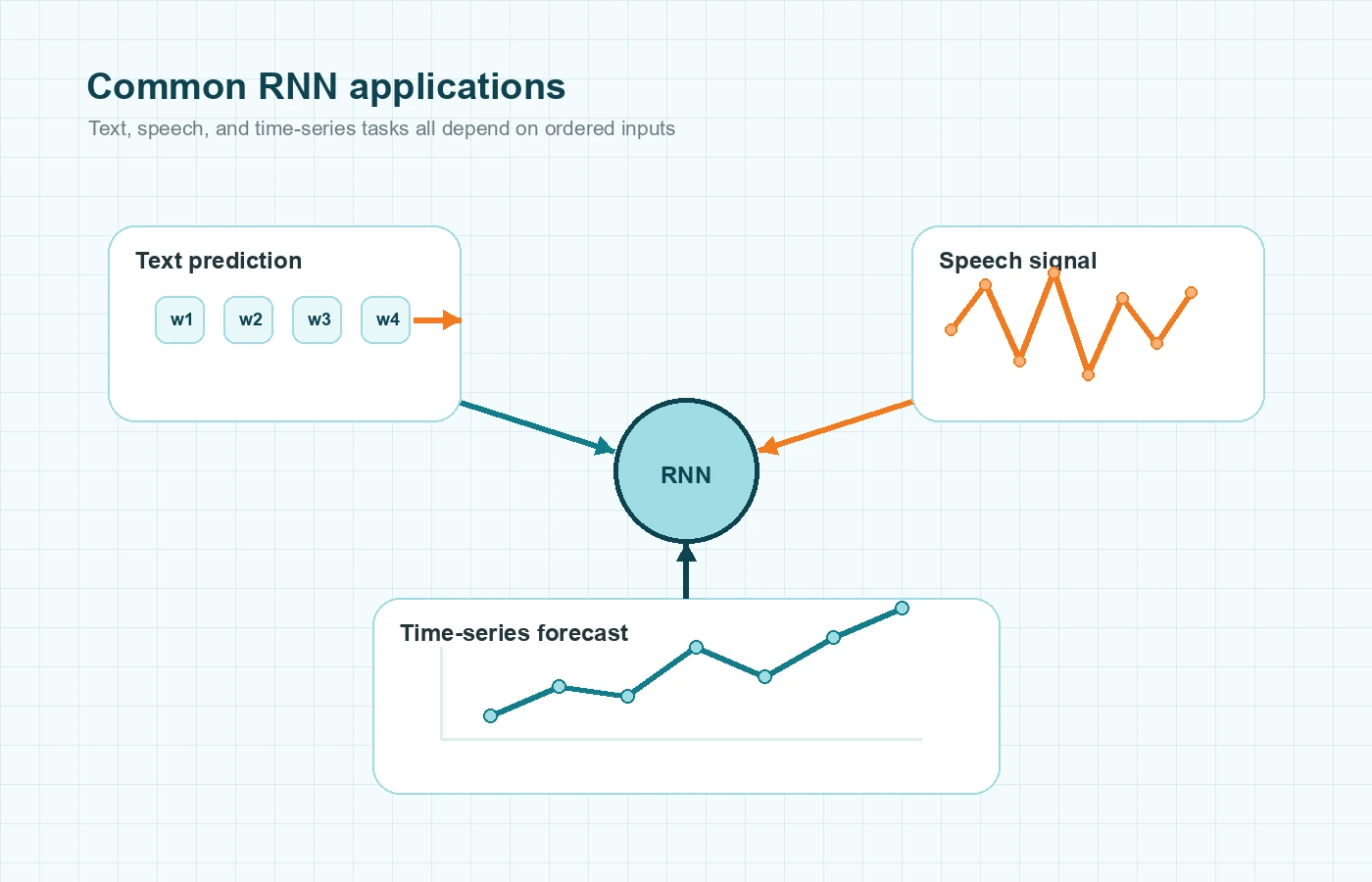
One classic example is next-word prediction. The model reads a sentence token by token and predicts what is likely to come next based on the earlier context.
Another example is sentiment analysis. “Good” and “not good” are close in vocabulary, but they are not close in meaning. Order changes the interpretation, so sequence-aware models make sense.
RNNs have also been used for sequence labeling tasks, where the model produces an output for each timestep. For example, it might assign a label to each word in a sentence or process a stream of inputs one step at a time.
Speech, sensor streams, and time series
IBM’s RNN overview highlights uses such as speech recognition, handwriting recognition, and time-series prediction. That range matters because it shows RNNs are not only language models. They are general tools for ordered data.
Time series is especially important for beginners who keep seeing the phrase neural networks for time series and wonder where RNNs fit. Suppose you want to forecast tomorrow’s temperature, estimate traffic for the next hour, or predict the next sensor reading in a machine-monitoring system. Those tasks all depend on the order of previous values.
Take a factory example. A single vibration reading might not say much by itself. But a rising pattern across many recent readings can signal a fault. An RNN can read that sequence step by step and learn from the pattern as it develops.
RNN vs CNN and other neural networks
Beginners often meet several neural-network terms at once, so it helps to place RNNs inside the broader family.
RNN vs CNN
RNNs are built for order over time or position in a sequence. CNNs, or convolutional neural networks, are built to detect local spatial patterns, especially in images and other grid-like data.
A short comparison helps:
- RNN: useful when the order of tokens or timesteps matters
- CNN: useful when local visual structure matters
If you want the image-focused counterpart to this topic, MindoxAI’s article on convolutional neural networks is the right follow-up.
RNN vs the broader ANN family
ANN, or artificial neural network, is the broad family name. RNN is one type inside that family. So an RNN is not separate from neural networks. It is a specialized design choice for sequence data.
That relationship clears up a lot of beginner confusion:
- ANN: broad category
- RNN: ANN built for ordered data
- LSTM and GRU: key RNN variants
- CNN: ANN built for image-like or grid-like data
If you want to zoom out from architecture design and look at how machine systems differ from human reasoning, MindoxAI’s piece on AI vs Human Intelligence is a useful broader-context read.
Final Thoughts
The clearest way to understand recurrent neural networks is to focus on the problem they solve. Some data only makes sense when you keep track of what came before. Language works that way. Speech works that way. Time series works that way too.
Once that idea clicks, the rest becomes easier. An RNN reads one step at a time, carries forward a hidden state, learns from sequence-level errors, and becomes useful when order matters. From there, LSTM and GRU stop feeling like random extra terms and start looking like what they really are: practical ways to help recurrent networks handle longer, messier sequences.