Graphs are everywhere once you start looking for relationships instead of isolated rows of data. Social networks connect people. Citation networks connect papers. Molecules connect atoms. If terms like nodes, edges, message passing, node classification, and link prediction still feel abstract, this guide is meant to make them usable. You will learn what graph neural networks are, why graph machine learning needs them, how Graph Neural Networks work, and where models like GCN, GraphSAGE, and GAT fit. By the end, you should have a clear mental model rather than a pile of disconnected definitions.
Why graphs need a different kind of neural network
Most neural networks are easiest to understand when the data has a fixed structure. A spreadsheet gives you rows and columns. An image gives you a grid of pixels. A sequence model reads one step after another in order. Graphs are different. As Distill’s introduction to graph neural networks explains, real-world graphs can vary widely in the number of nodes, edges, and connection patterns, which makes them awkward to force into the rectangular formats that standard deep-learning pipelines expect.
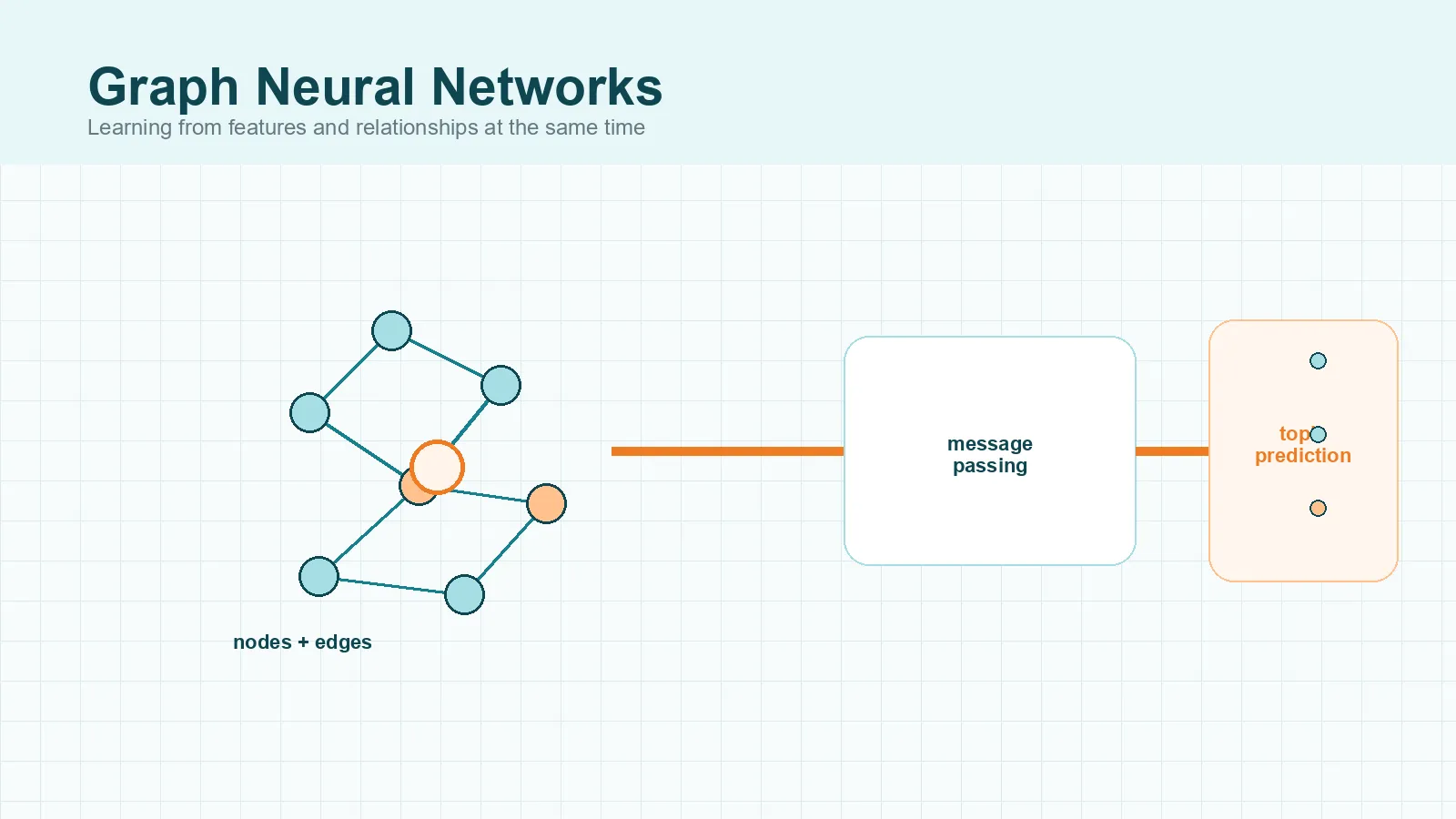
A graph is built from nodes and edges. Nodes represent entities such as people, papers, products, roads, or atoms. Edges represent relationships such as friendship, citation, co-purchase, road links, or chemical bonds. The shape is irregular: one node may have two neighbors while another has two thousand.
That irregular structure changes the learning problem. Imagine a table of users on a social platform. You can store age, city, and interests in columns, but that still misses the most important question: who is connected to whom? If two users interact with the same group of people, that relationship may say more than any single profile field. A regular feedforward network can learn from user features, but it does not naturally learn from the network around each user. That is the gap graph neural networks are designed to fill.
What a graph neural network is
A graph neural network, or GNN, is a neural network designed to learn from graph-structured data. Instead of looking at one item in isolation, it learns from both the item’s own features and the structure around it. The Springer review of graph neural networks describes GNNs as deep-learning models that learn from graph data through message passing between connected nodes.
Take a citation network as a simple example. Each paper is a node. A citation from one paper to another is an edge. Each paper can also have features, such as keywords, topic information, or an embedding of its abstract. A GNN does not ask only, “What does this paper say?” It also asks, “Which papers is it connected to, and what can those neighbors tell us?”
This is why GNNs are often described as models that combine attributes with relationships. A node’s final representation is not just a copy of its original features. It becomes a learned summary of the node and part of its neighborhood. That learned summary is often called an embedding, which simply means a compact numerical representation the model can use for prediction.
How graph neural networks work
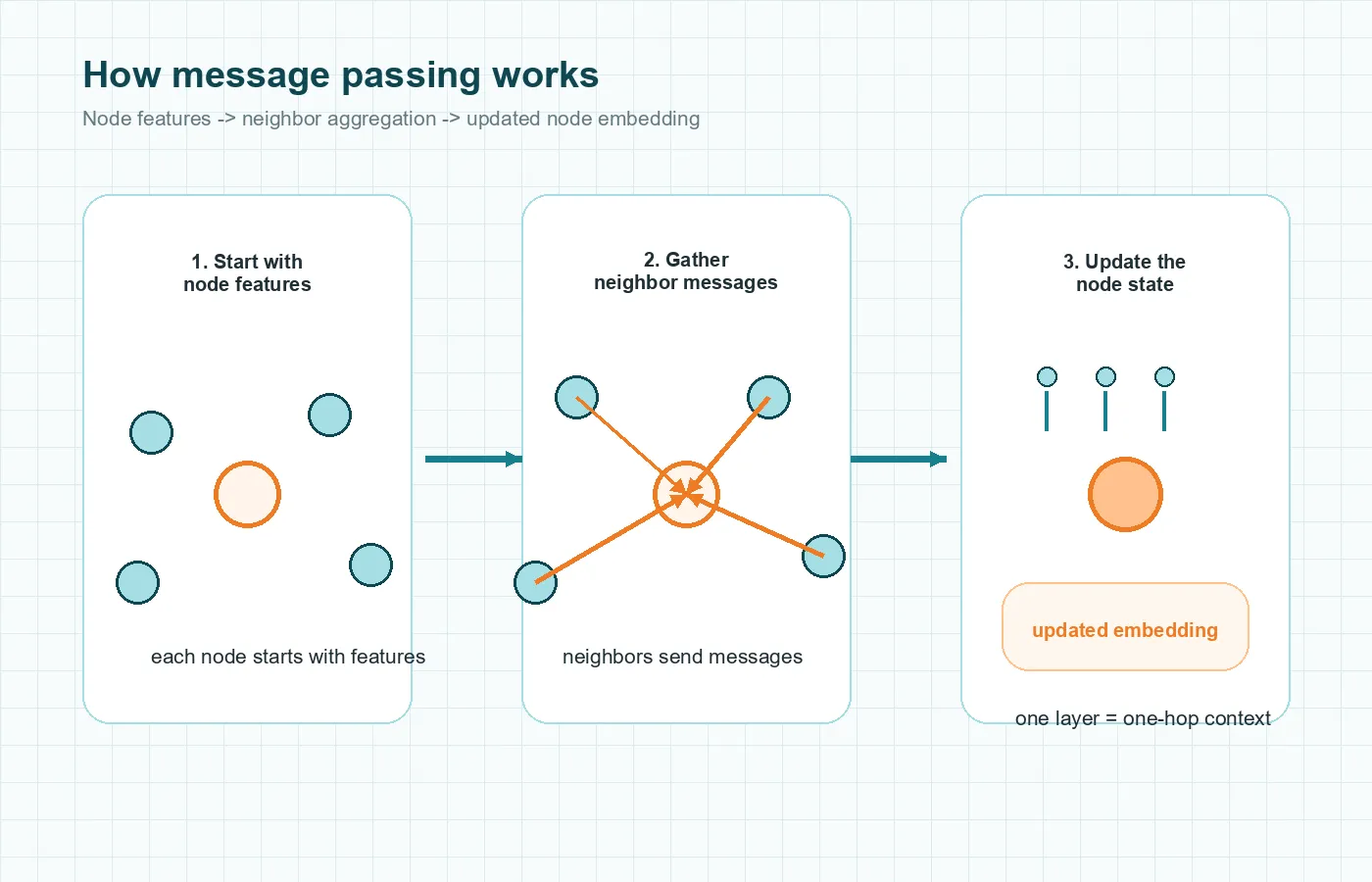
The central idea behind how Graph Neural Networks work is message passing. In plain language, nodes exchange useful information with their neighbors, and the network learns how to combine that information. The Neural Message Passing for Quantum Chemistry paper made this framing especially influential.
Start with node features
Each node begins with its own features. In a fraud graph, a node might represent an account with features such as transaction count, device type, or region. In a molecule graph, a node might represent an atom with features such as atom type and charge.
Send, aggregate, and update messages
The node then gathers signals from connected nodes and, in some models, connected edges too. Those neighboring signals are the messages. After that, the model aggregates them using an operation such as a sum, mean, max, or a learned weighting scheme. Finally, a neural-network layer updates the node representation.
This sounds abstract until you picture a citation graph. Suppose you want to predict the topic of a paper. The paper’s own words matter, but so do the papers it cites and the papers that cite it. If many nearby papers discuss graph machine learning, that neighborhood context should affect the prediction.
Why multiple layers matter
One GNN layer usually lets a node gather information from one hop away, meaning its direct neighbors. Two layers let it gather information from neighbors of neighbors. This is one reason stacking layers matters: the node can “see” farther into the graph.
That same idea also explains a limitation. Going deeper does not automatically help forever. If too many layers keep mixing neighborhood information, different nodes can start to look too similar. The article on Distill also highlights that long-range information is difficult enough that some graph architectures add global context vectors or master nodes to help bridge distant parts of the graph.
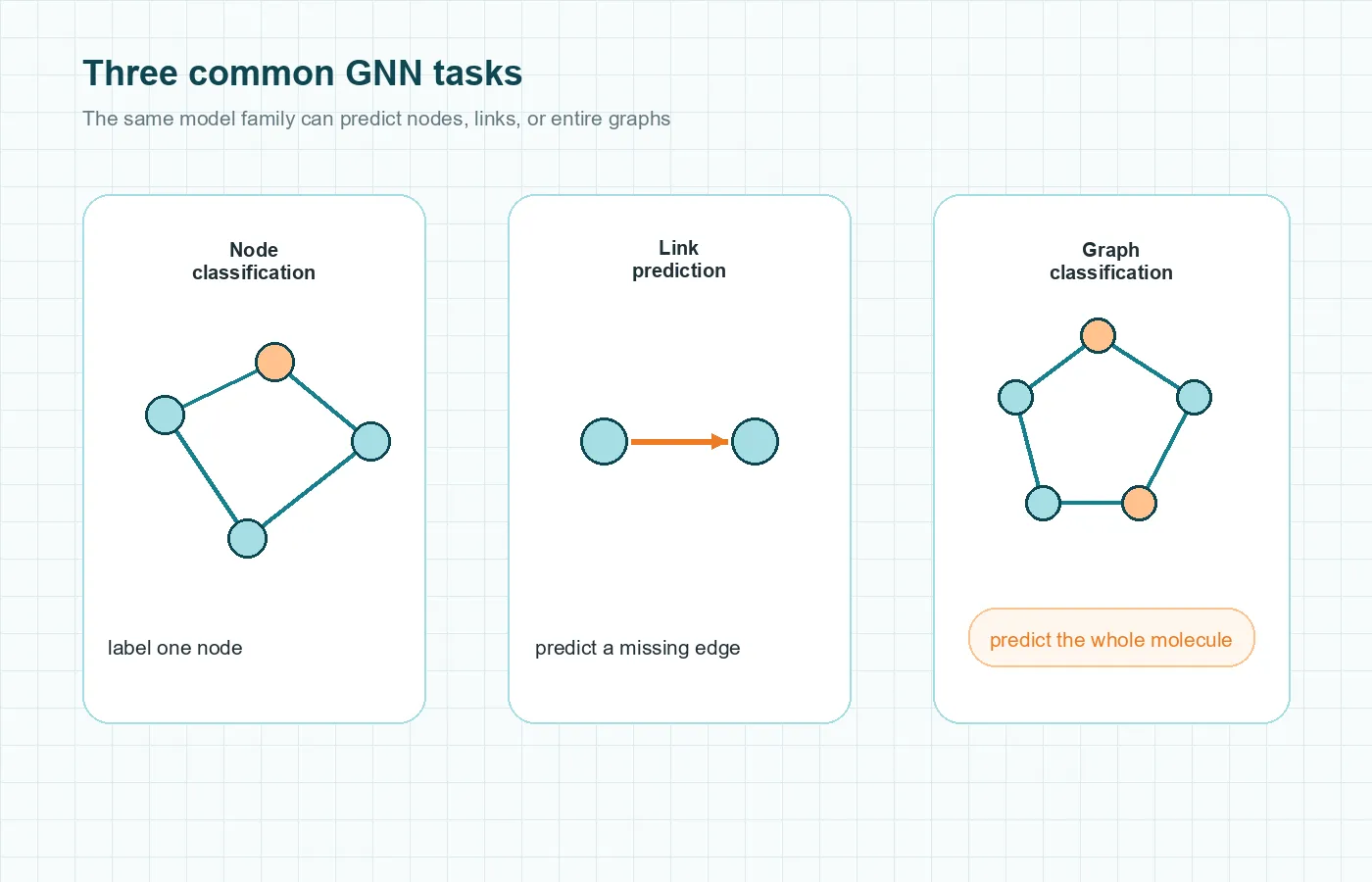
The three main GNN task types
One reason many GNN explained articles feel scattered is that the same model family is used for different prediction goals. The cleanest way to organize them is by asking what you want to predict. Distill separates graph tasks into graph-level, node-level, and edge-level predictions, while the Springer review groups the practical downstream tasks into node classification, link prediction, and graph classification.
Node classification
In node classification, the goal is to assign a label to a node. That could mean classifying a user as likely spam, classifying a paper by topic, or classifying a protein by function. The graph helps because nearby nodes often carry useful clues.
Link prediction
In link prediction, the goal is to predict whether an edge should exist between two nodes or what kind of relationship that edge represents. If you have ever seen a “People You May Know” suggestion, the underlying problem can be framed as link prediction. The same idea appears in recommendation systems and biomedical interaction networks.
Graph classification
In graph classification, the goal is to label a whole graph. A molecule is the classic example. Each molecule has its own graph structure, and the task may be to predict toxicity, solubility, or some other property of the entire molecule. This is useful because not every graph question is about a single node. Sometimes the question is about the whole structure.
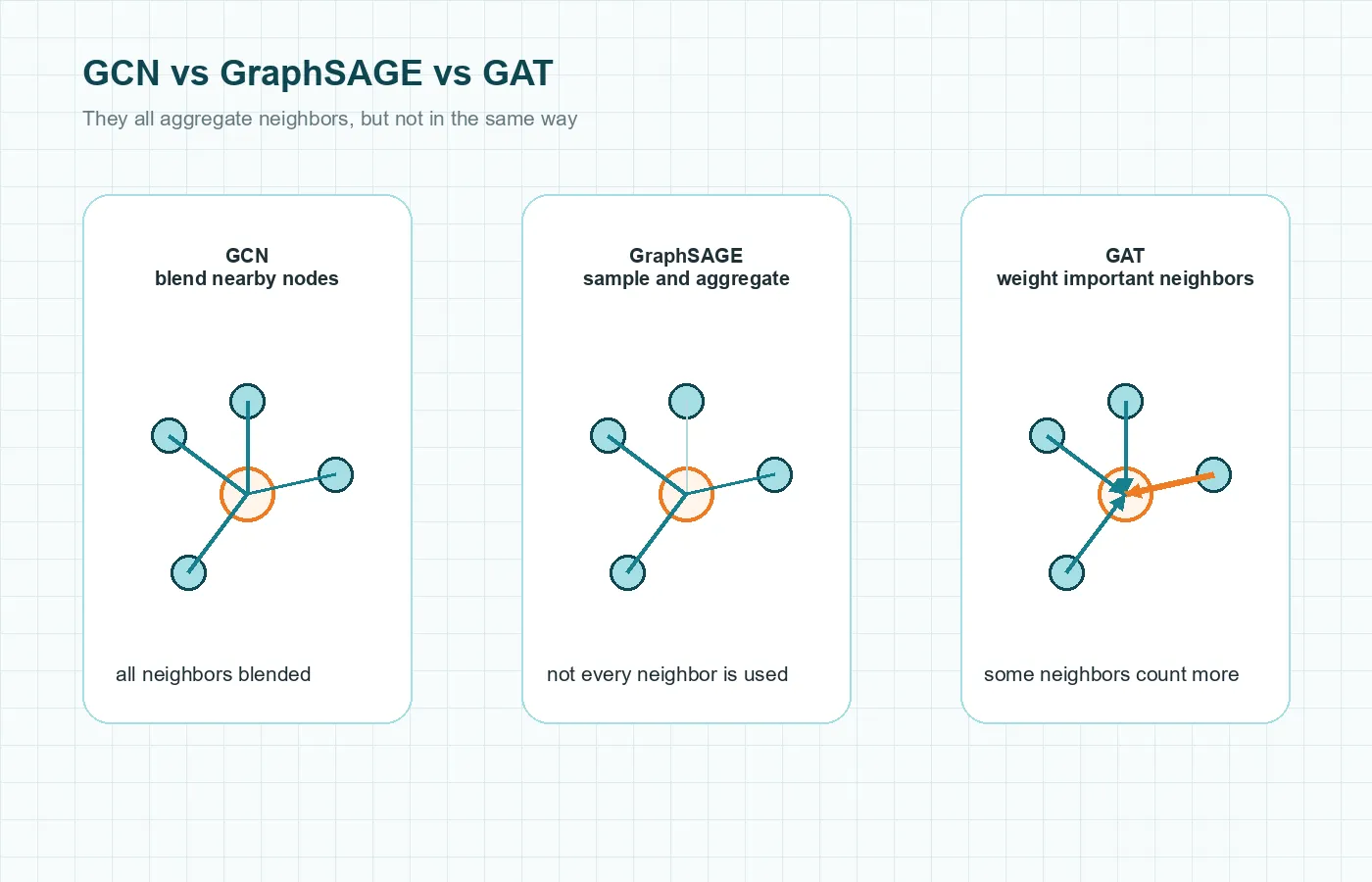
Common types of graph neural networks
GNN is the family name. Inside that family are different architectures that change how neighborhood information is combined.
Graph Convolutional Networks (GCNs)
The GCN paper by Kipf and Welling became foundational because it gave researchers a practical way to apply convolution-like thinking to graphs. The simplest beginner intuition is neighborhood smoothing: a node updates itself by mixing its own features with information from nearby nodes. That makes GCNs a good mental starting point for citation-network node classification.
GraphSAGE
GraphSAGE stands for Graph Sample and Aggregate. Its key idea is practical: instead of depending on a fixed embedding table for every node seen during training, it learns an aggregation function that can be applied to new or unseen nodes too. That makes it useful for large or evolving graphs where new users, products, or documents keep arriving.
Graph Attention Networks (GATs)
Graph Attention Networks add attention to the neighborhood step. Rather than treating every neighbor equally, the model learns that some neighbors should carry more weight than others. If a paper cites ten other papers, a GAT can learn that only a few are especially informative for the current prediction.
Message-passing models
Message Passing Neural Networks are especially useful when both nodes and edges carry important information. Molecules are the standard example because the type of bond matters, not just the atoms themselves.
Real-world Graph Neural Network applications
Graph Neural Network applications make the topic feel more grounded because you can see why graph structure matters.
In a recommendation graph, users, items, clicks, purchases, and similarities can all be represented as relationships. A GNN can learn from those connections to improve recommendations. Instead of scoring an item only from a user’s profile, the model can also learn from nearby products, similar users, and interaction patterns.
Fraud detection is another strong fit. Fraud rarely appears as one isolated transaction. It often shows up as a suspicious pattern of related accounts, devices, merchants, or transfers. Two transactions that look harmless on their own can become suspicious when seen inside a larger graph of repeated links.
Molecules and drug discovery are another clear example. A molecule is already a graph: atoms are nodes and bonds are edges. GNNs can learn molecular properties without flattening the structure into a simple feature vector. Knowledge graphs, search systems, and traffic networks follow the same logic: the relationships are part of the signal.
GNN vs ANN, CNN, and RNN
Beginners often meet several neural-network names at once, so it helps to place GNNs in the broader picture.
An artificial neural network is the broad family name. A simple feedforward network works well when the input is a fixed set of features.
A convolutional neural network is specialized for grid-like data such as images. It uses local filters that slide over spatial neighborhoods.
A recurrent neural network is specialized for sequences, where order matters from one step to the next.
A GNN is specialized for graphs, where the important structure is not a grid or a simple left-to-right sequence but a network of relationships.
The comparison is easier with one example. A feedforward network fits fixed house features, a CNN fits an image of a house, an RNN fits a sentence about a house, and a GNN fits a neighborhood of houses connected by roads, utilities, or transaction links.
So GNNs do not replace other neural networks. They solve a different structural problem.
Strengths and limitations of GNNs
GNNs are powerful because relationships are often part of the signal. Many standard models treat each item as mostly independent. GNNs can learn that context from the graph itself.
Where GNNs shine
- They combine node features with neighborhood structure.
- They support node-level, link-level, and graph-level tasks in one broad family.
- They are a natural fit when the graph already exists in the problem, such as molecules, citation networks, and recommendation graphs.
Where they struggle
- Graph construction matters. If the graph is noisy or poorly defined, the model learns from weak relationships.
- Very large graphs are hard to train on efficiently.
- Long-range dependencies remain difficult because most GNN layers mix local neighborhoods first.
- If you stack too many layers, node representations can become too similar.
- Interpretability is still a challenge, even when the model clearly benefits from relational structure.
That balanced view matters. GNNs are a strong tool for relational data, but they are still one tool among many. If you want a broader reminder that powerful pattern recognition is not the same thing as human-style reasoning, MindoxAI’s article on AI vs Human Intelligence is a useful follow-up.
Final Thoughts
The simplest way to understand graph neural networks is to stop thinking about isolated records and start thinking about connected systems. A GNN learns from a node’s own features, but it also learns from the neighborhood around that node. That is why message passing sits at the center of the field.
Once that idea clicks, the rest becomes easier. Node classification, link prediction, graph classification, GCNs, GraphSAGE, GATs, and graph deep learning all sit on the same foundation: learning from both attributes and relationships. That is what makes GNNs different, and that is why they matter.