If terms like convolution layer and pooling layer keep showing up in AI articles, this guide is here to make them plain. You will learn what convolutional neural networks are, why they work so well for image recognition, how a CNN reads an image step by step, and where these models still matter in deep learning today. By the end, phrases like CNN in deep learning, feature map, and computer vision neural networks should feel clear enough to explain in your own words.
What a convolutional neural network is in simple terms
A convolutional neural network, or CNN, is a type of neural network built to work especially well with images and other grid-like data. Instead of treating every pixel as a separate input with no position, a CNN looks for small patterns that repeat across an image, such as edges, corners, curves, or textures.
That design matters because images are not random lists of numbers. A photo has structure. Nearby pixels usually belong to the same surface or shape. A CNN is built to notice that local structure.
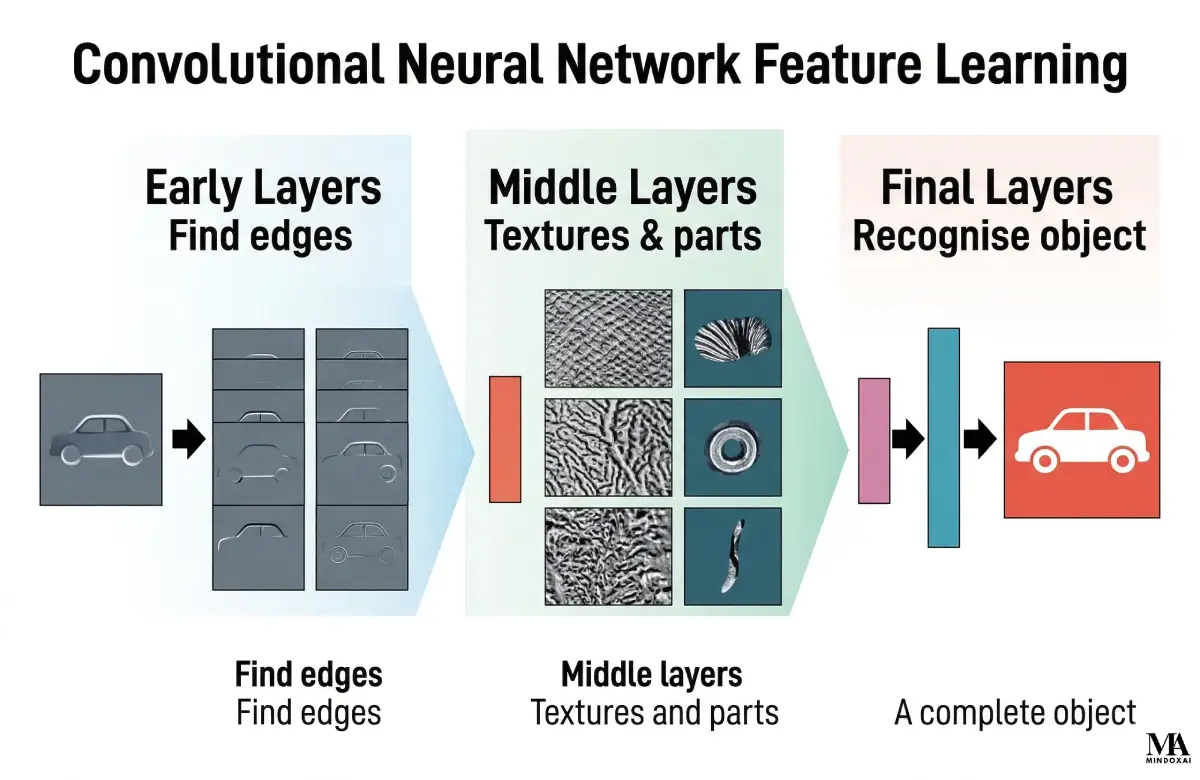
Think of it this way. If you show a picture of a cat to a person, the person does not memorize every pixel one by one. They notice ears, whiskers, eyes, fur, and overall shape. A CNN works in a similar spirit. Early layers pick up simple patterns. Later layers combine those smaller patterns into more meaningful ones.
This idea sits at the heart of deep learning for vision. The classic paper by LeCun, Bottou, Bengio, and Haffner helped establish trainable convolutional networks for document recognition, and the same core logic still explains why CNNs are useful today.
Why CNNs work better on images than plain neural networks
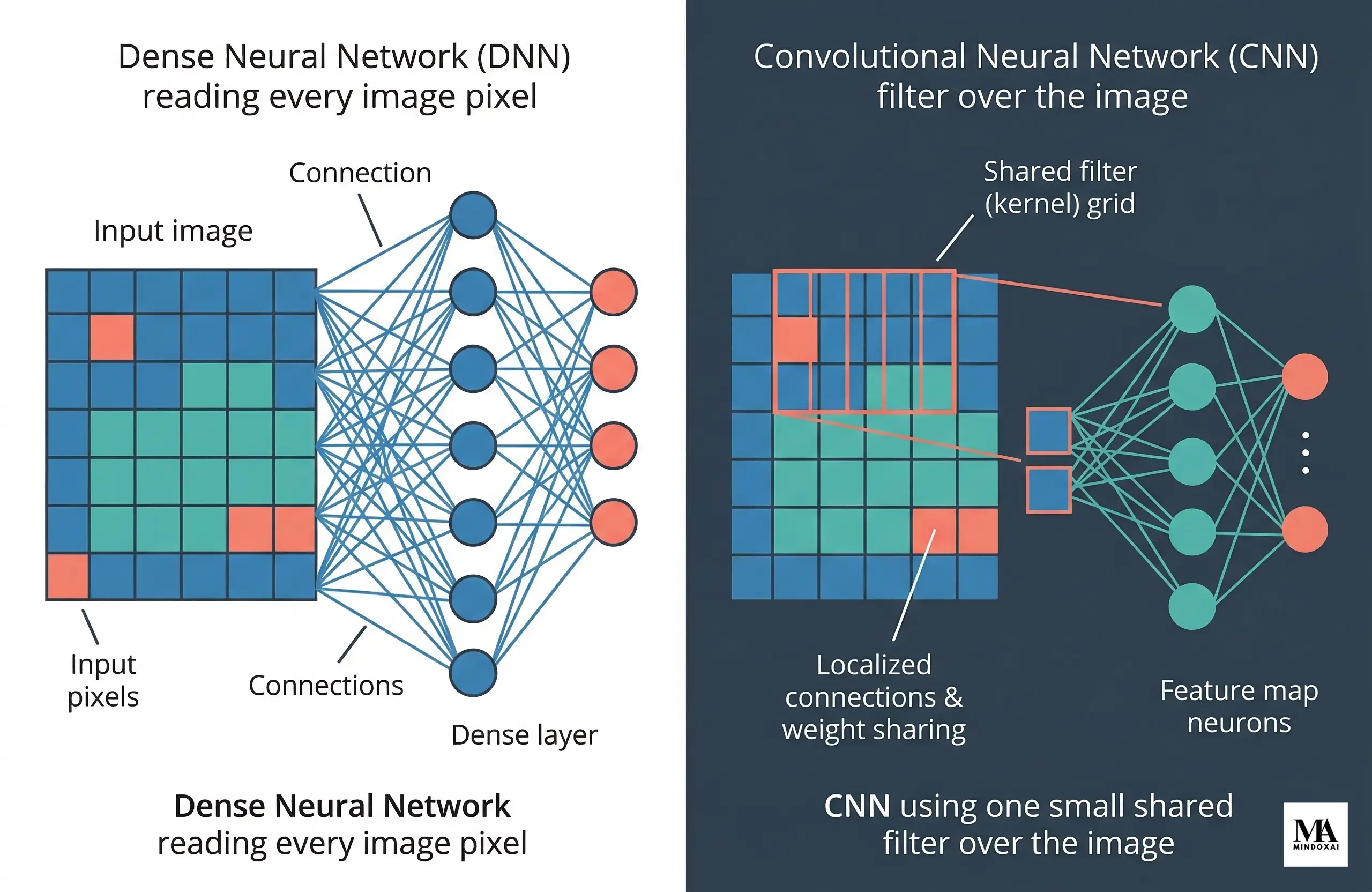
To understand convolutional neural networks explained clearly, it helps to compare them with a regular fully connected neural network. In a dense network, every input value connects to every neuron in the next layer. That can work for small problems, but images create a scale problem almost immediately.
Imagine a grayscale image that is 200 pixels by 200 pixels. That is 40,000 input values before you even count color channels. If every one of those values connects to every neuron in the next layer, the number of parameters grows fast. Training becomes heavier, memory use increases, and the model can overfit, which means it learns the training data too closely and struggles on new images.
CNNs reduce that burden in two important ways. First, they use local connectivity. A neuron does not inspect the whole image at once. It looks at a small patch, such as 3×3 or 5×5 pixels. Second, they use parameter sharing. The same filter is reused across the full image, so the model does not have to learn a different edge detector for every possible location.
That is a practical advantage, not just a mathematical one. A vertical edge is still a vertical edge whether it appears on the left side of a photo or the right side. CNNs are designed to take advantage of that repeatability.
If you want a broader comparison between machine perception and human cognition, AI vs Human Intelligence: Key Differences and Similarities is a useful companion read.
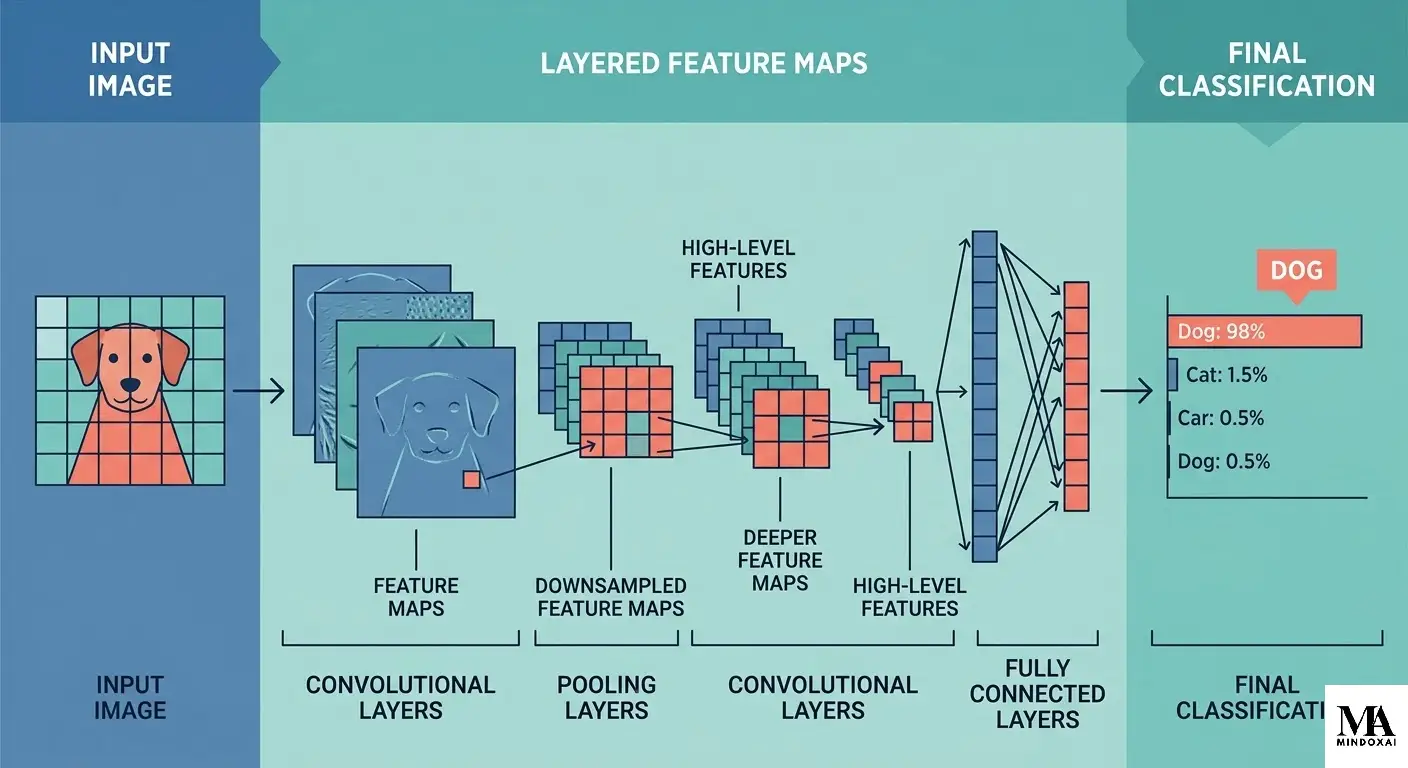
How convolutional neural networks work step by step
The easiest way to understand how convolutional neural networks work is to follow one image through the network.
Convolution layer
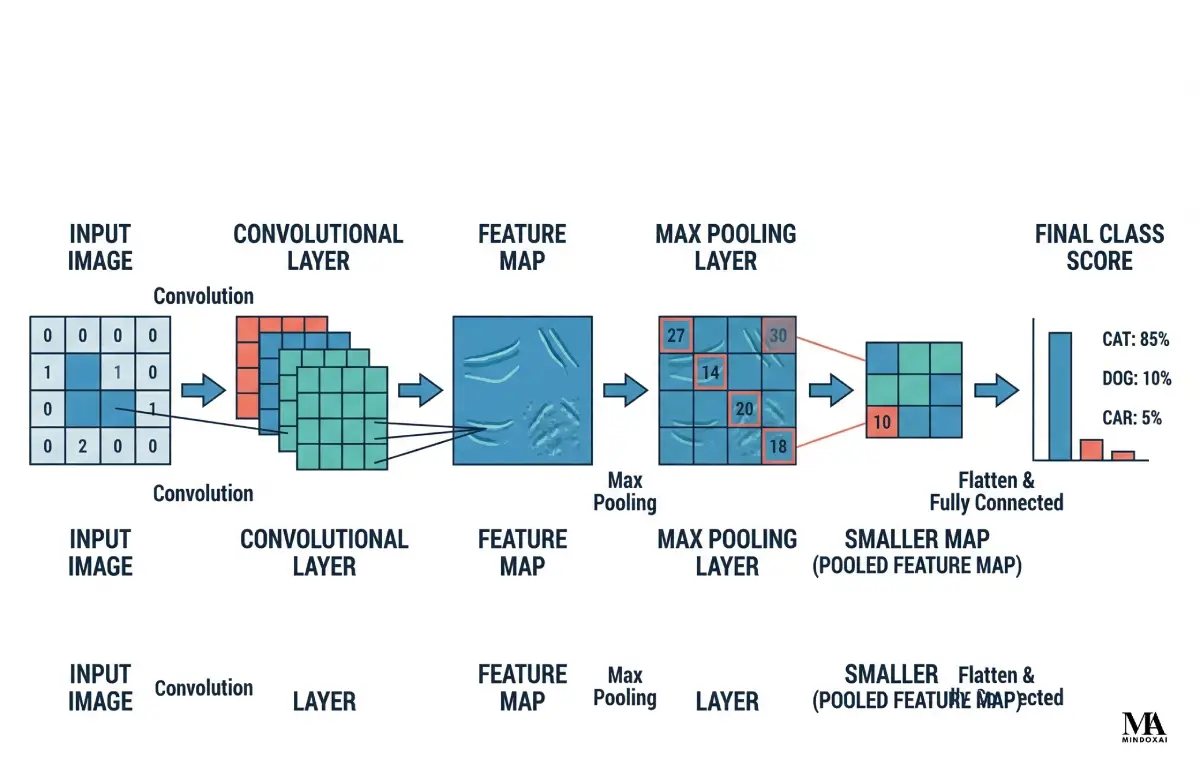
The convolution layer is the core part of a CNN. A small filter, also called a kernel, slides over the image and performs the same calculation at each position. The output is called a feature map, which is simply a new grid showing where that filter responded strongly.
Suppose one filter is good at spotting vertical edges. As it moves across the image, it produces larger values wherever a strong vertical boundary appears, such as the side of a handwritten digit or the edge of a door. Another filter may respond to horizontal edges. Another may respond to curves.
The network usually does not begin with these filters already known. It learns them during training. That is why a convolution layer is best understood as a trainable pattern detector that scans the image for recurring visual clues.
Activation and feature maps
After convolution, the network usually applies an activation function such as ReLU, short for rectified linear unit. ReLU keeps positive values and sets negative values to zero. That simple rule helps the model keep useful signals while learning more complex patterns.
The resulting feature maps become the input to the next layer. Early feature maps may highlight simple edges. Later feature maps may highlight combinations like corners, textures, eyes, wheels, or other larger shapes. In plain language, feature maps are the notes the network writes to itself about what it thinks it sees.
Pooling layer
A pooling layer reduces the size of a feature map. The most common beginner example is max pooling. In max pooling, the network looks at a small region such as 2×2 and keeps only the largest value.
Imagine a 2×2 block with values 1, 3, 2, and 9. Max pooling keeps 9. Some detail is lost, but the strongest signal survives. That often makes the model smaller and more robust. If an important feature shifts by a pixel or two, the network can still keep the main clue.
Pooling is common in introductory CNN designs, though not every modern CNN uses classic pooling in exactly the same way. The main idea still holds: reduce detail while preserving strong evidence.
Final classifier layers
After several rounds of convolution and downsampling, the network has a stack of higher-level features. At that stage, a final set of layers turns those features into a prediction such as cat, dog, stop sign, or pneumonia.
In many teaching examples, the feature maps are flattened and passed to one or more dense layers. In other models, the final prediction step is arranged a little differently. The core logic stays the same: use learned visual evidence to choose the most likely label.
A simple way to remember the pipeline is this:
- convolution finds patterns
- activation keeps useful signals
- pooling reduces size
- later layers combine small patterns into larger ones
- final layers choose the class
A simple example of a CNN reading one image
Now make the process concrete. Imagine a CNN is trying to recognize a handwritten number 8 from a small grayscale image. The first convolution layer scans the image with several filters. One filter reacts strongly to vertical edges. Another reacts to curves. Another reacts to enclosed loops.
Because the digit 8 has two rounded loops, some feature maps light up around those curved boundaries. The next layers combine those earlier signals. Instead of only asking, “Is there an edge here?” the network starts asking more complex questions like, “Do these edges form a closed shape?” or “Do two rounded loops appear one above the other?”
Pooling reduces the feature map size so the network keeps the strongest clues without carrying every pixel-level detail through the whole system. By the time the data reaches the final classifier, the model is no longer working with raw pixels. It is working with learned features that represent the structure of the digit.
The same logic scales to photos. A CNN for image recognition may first detect lines, then textures, then object parts like ears or wheels, and finally whole categories such as cat, car, or bicycle. That hierarchy is one reason CNNs became so effective for vision tasks.
Common uses of CNNs in deep learning
CNNs became famous because of image classification, but their use across computer vision neural networks is broader than that. The breakthrough paper known as AlexNet showed how deep CNNs could scale to large image recognition tasks, and later architectures pushed that progress further.
One common use is photo classification. A phone gallery app can sort images into categories like food, pets, or landscapes. Another use is object detection, where the model identifies not only what is in the image but also where it appears. CNN-based ideas also appear in image segmentation, where each pixel or region gets a label.
CNNs are also used in medical imaging. A model can help spot suspicious patterns in X-rays, CT scans, or pathology slides. In manufacturing, CNNs can inspect products for scratches, missing parts, or surface defects. In security systems, they can help with face detection or scene analysis.
That does not mean one CNN handles every visual task in the same way. A model built for classifying one image is not identical to a model built for detection or segmentation. Still, the shared idea remains consistent: learn visual patterns directly from data instead of hand-coding every rule.
Strengths and limits of CNNs
CNNs have real strengths. They are more efficient than dense networks on images because they reuse filters across space. They preserve spatial structure better than a plain feedforward network. They also learn features automatically, which reduces the need for hand-designed image rules.
That explains why CNNs became a standard building block in vision. Papers like VGG and ResNet showed how deeper and better-structured CNNs could improve large-scale image recognition.
But CNNs also have limits. They usually need substantial data to perform well. They can struggle when important information depends on very long-range relationships across the image. They can also become brittle when the training data does not represent enough variation in scale, background, lighting, or viewpoint.
A simple comparison helps. A CNN is often excellent at spotting local visual clues, like fur texture or the edge of a wheel. Some tasks, however, depend more heavily on broad scene context or relationships between far-apart regions. That is one reason newer and hybrid vision architectures continue to appear.
It also helps to remember that CNNs are still specialized systems. They can be extremely strong at visual pattern recognition without becoming general intelligence. If you want that wider contrast, see what AGI means in simple terms.
Do CNNs still matter today?
Yes. CNNs still matter, both in practice and in education.
They may no longer dominate every research headline, but they remain useful because they are efficient, well-understood, and effective on many visual tasks. The official TensorFlow image classification tutorial still teaches a standard CNN stack with convolution blocks, max pooling, and a dense classifier because that remains a strong starting point for image problems.
Historically, architectures such as LeNet, AlexNet, VGG, and ResNet showed how CNNs could move from document recognition to large-scale visual recognition with deeper and more capable designs. That sequence still shapes how many engineers and students understand image models.
So even if you later study newer vision architectures, learning CNNs is not wasted effort. It gives you the vocabulary for filters, receptive fields, feature maps, and hierarchical feature learning. It also gives you one of the clearest examples of how deep learning learned to handle images at scale.
For a wider discussion of what current AI systems can and cannot do beyond narrow tasks, Why AI Still Can’t Think Like a Human Mind is a relevant follow-up.
Final Thoughts
Convolutional neural networks become much easier to understand once you stop seeing them as mysterious math and start seeing them as layered pattern detectors. A CNN looks for small visual clues first, then combines those clues into larger meaning.
That is the core answer to what are convolutional neural networks. They are neural networks designed to read structured visual data in a smarter and more efficient way than a plain dense network can. If you remember one mental model, make it this: a convolution layer finds patterns, a pooling layer condenses them, and the later layers use those patterns to decide what the image most likely shows.